2020-05-14
We released Fastnate 1.5.0 which enhances the import from CSV and XML files and offers the generation of Liquibase filesIntroduction
-

-
This is Nate.
Nate is a software developer. (I know, we've just lost half of the audience ... )
Nate is a Java developer. (Now we've lost the other half, except ... you)
Nate likes many things. He likes programming, he likes agile software development, he likes if things fit together.
-

-
Nate has worked in many software projects that make use of a database.
So he learned to know JPA to map his objects to a relational database. He learned that if he refactors one of his entity classes, he doesn't have to think about the generated SQL, as JPA will do that for him. He has learned that JPA is fast for read operations on the database. And he has learned that JPA is fast enough for atomic write operations.
And now Nate is a cool Java developer.
-

-
What Nate is missing in JPA is a strategy for importing initial data or test data into either the development or the production database.
If the customer has an existing database which hasn't to be changed for the tasks that Nate is working on, everything is fine.
But if either he starts with an empty database, or if the existing database has to be changed, or if he has no access to that database, than he needs some way to fill the data into his database. Unfortunately this situation is the case for the majority of his projects.
Nate found out that he has two options:
He could use JPA to create and fill his database on the fly.
The biggest problem with that is, that JPA is slow for write operations, as in most cases it needs some additional read statements before or after the update, it needs to update resp. flush its caches and it has a complex transaction management. During the lifetime of an application this is not really a problem, but during setup of a database this can take some time. And if he (or one of his teammates) changes the content or layout of the database, he has to do it again and again.
And eventually it may block refactorings or enhancements, because nobody likes to wait.
As another option he could write all the necessary SQL insert and update statements by hand and import these statements through one of the SQL interfaces.
This option is much faster than the JPA alternative, but has some other disadvantages. First of all he needs to know SQL. Although it is advisable to understand SQL for working with JPA, it is not really necessary. Furthermore he has to know the exact design as created by his JPA library. And the written SQL would be specific for that JPA library and, more important, for his current database. If Nate switches to another database type or version he has to change the SQL. If he uses a different database type during development and testing (e.g. H2 and Oracle), he would have to maintain two slightly different SQL statement sets.
And finally it would block refactorings as well, because if he changes one of his entity classes he needs to change the SQL as well.
Nate has tried both options, even at the same time. And in every new project he has the feeling that there has to be a third option.
-

-
So Nate thought, and he thought, and finally he got the idea.
If he uses the JPA entities to generate the SQL statements ... that would be fast, that would be database independent, he could refactor as he like, he wouldn't have to think about SQL, ...
But he couldn't use any of the existing JPA libraries, as these were not designed to create an offline SQL script.
So Nate decided to write his own library on top of JPA. It should not replace any existing JPA library, it was meant as an add-on.
And finally Nate managed it. And now he is ... the Fast Nate.
-
Comparison of available options
A short summary of the pros and cons of every available option for generating data.
Feature JPA SQL Fastnate Independent of database dialect yes no yes Easy refactoring of entity classes yes no yes Generate offline, apply later no yes yes Fast import no yes yes* -
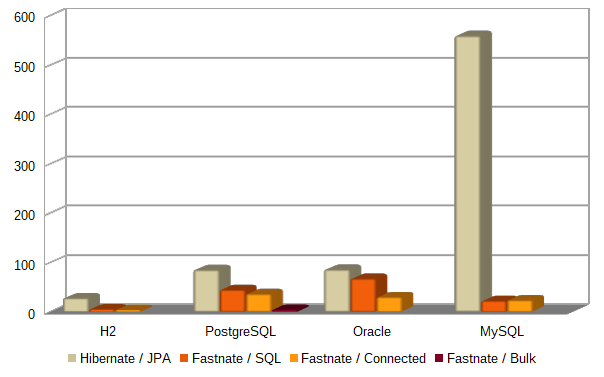
A comparison chart of the performance of Hibernate and Fastnate
Documentation
The documentation and examples of Fastnate are maintained in the Fastnate Wiki.
Some Wiki shortcuts:
- First steps
- How-Tos:
- FAQ:
- How can I integrate Fastnate into my own project?
- What types of databases are supported?
- Which JPA implementations are supported?
- Which JPA features are supported?
- Which validators are applied during creation of SQL?
- Are mapping files supported?
- Why didn't the import-data task rewrite my SQL file, I've changed something relevant?
- I'm missing a feature in Fastnate. What can I do about it?
The latest generated API documentation can be found in the API section.
Some API shortcuts:
- Latest JavaDoc for fastnate-data
- Latest JavaDoc for fastnate-generator
- Description of the Maven goal import-data
Finally a small appetizer of how to use the Fastnate Data library:
public class TestData extends AbstractDataProvider {
/** A list that contains all the created data. */
@Getter
private final List<ExampleEntity> entities = new ArrayList<>();
/** Create the entities. */
public void buildEntities() throws IOException {
this.entities.add(new ExampleEntity("Example Entity"));
ExampleEntity entity2 = new ExampleEntity("Example Entity 2");
entity2.getChildren().add(new ExampleEntity("Child"));
this.entities.add(entity2);
}
}
See the download section for a description how you can add the Fastnate library to your build path.
You can generate the SQL for your entities either during build time or during application startup with one of the following options:
- Use the Maven build task
-
You can use the importData task to generate an offline SQL file during build time:
<build> <plugins> <plugin> <groupId>org.fastnate</groupId> <artifactId>fastnate-maven-plugin</artifactId> <version>1.5.0</version> <executions> <execution> <goals> <goal>import-data</goal> </goals> <configuration> <packages>... your root package ...</packages> <dataFolder>... your data folder, if you import data from files ...</dataFolder> </configuration> </execution> </executions> </plugin> </plugins> </build>
- Command line
-
You can generate the SQL file from the command line:
java -cp ...;fastnate-data.jar;fastnate-generator.jar -Dfastnate.data.provider.packages=your.root.package org.fastnate.data.EntityImporter [SQL file]
If you don't specify any SQL file, the default is used: data.sql
- Application startup
-
You can import your data on application startup, for example directly after a clean database is created by Hibernate. This is usually much faster than the plain SQL import (see the performance chart above). Tho configure that you need to define a SessionFactoryObserver in your persistence.xml:
<persistence ...> <persistence-unit ...> <properties> <!-- Tell Hibernate to recreate the schema on every startup. You could even define that as a system property, to decide depending on the environment. --> <property name="hibernate.hbm2ddl.auto" value="CREATE" /> <!-- Tell Hibernate to use our SessionFactoryObserver --> <property name="hibernate.ejb.session_factory_observer" value="org.fastnate.data.DatabaseStartupImport" /> <!-- Add any fastnate specific properties here --> <property name="fastnate.data.provider.packages" value="... your root package ..." /> <property name="fastnate.data.folder" value="... your data folder, if you import data from files ..." /> </properties> </persistence-unit> </persistence>
Fastnate will only run, if hibernate.hbm2ddl.auto is set to CREATE or CREATE-DROP. If you would like to use another strategy (or if you are still using Fastnate pre 1.5.0), create your own SessionFactoryObserver and use DatabaseStartupImport as blueprint.
Download Fastnate
You can obtain Fastnate in different flavours. For an overview of available versions see below.
- Include Fastnate as Maven dependency
-
Fastnate is included in the central Maven repository. Just add it to
your pom.xml:
<dependencies> <!-- Use the DataProvider --> <dependency> <groupId>org.fastnate</groupId> <artifactId>fastnate-data</artifactId> <version>1.5.0</version> </dependency> <!-- Or use the generator itself --> <dependency> <groupId>org.fastnate</groupId> <artifactId>fastnate-generator</artifactId> <version>1.5.0</version> </dependency> </dependencies>
- Standalone
- If you want to use Fastnate as standalone library, you need to download it from our binary repository:
- Snapshot builds
-
To use the latest development snapshots as dependency you need to add our binary repository to your
settings.xmlorpom.xml:After that you can switch to version 1.6.0-SNAPSHOT in your dependency declaration.<repositories> <repository> <id>fastnate.org</id> <url>https://download.fastnate.org/repository</url> <snapshots> <enabled>true</enabled> </snapshots> </repository> </repositories>
- Latest sources
- The sources are available in GitHub: You can browse or clone the source here:
Versions of Fastnate
Stable versions
- 1.0.0-RC1
- Support for Java 7 and JBoss AS 7.x / Hibernate 4
- 1.1.0
- Support for Java 8 and WildFly 10 / Hibernate 5
- 1.2.0
- Better support for different generator types and for MySQL
- 1.3.0
- Support for Microsoft SQL server and for writing statements to a database
- 1.4.0
- Improved performance and JPA compatibility and support to write PostgreSQL bulk files
- 1.4.1
- Bugfix release
- 1.5.0
- Enhances the import from CSV and XML files and offers the generation of Liquibase files
Changelog
The changelog is maintained in the repository in the file changelog.md.
Road map
An overview of upcoming versions can be found in our issue tracker.
Fastnate License
Fastnate is licensed under the Apache License, Version 2.0 (the "License"), you may not use it except in compliance with the License. You may obtain a copy of the License at
About Fastnate
Fastnate was initially created for the eGovernment Application Framework at ]init[ AG.
In 2014 the ]init[ AG gave their pemission to publish Fastnate as standalone library under an OpenSource license.
Fastnate is now maintained by Tobias Liefke.
Contributors:
- Andreas Penski
- Heiko Schefter
- André Babinski
- Mathieu Lavigne
If you would like to contribute to Fastnate, you can create a pull request.
Or you create a new issue in the Fastnate bug tracking system and add your patch to it.